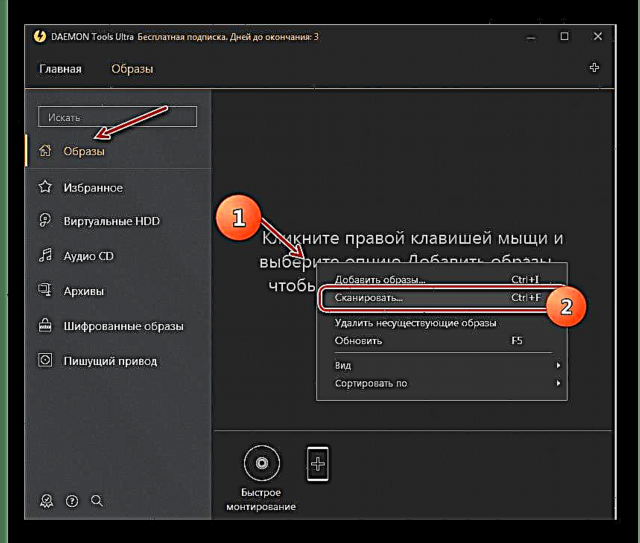
Betidanik urrun dago testua PDF fitxategi batetik ateratzea ohiko kopiak erabiliz. Horrelako dokumentuen orrialdeak paperezko bertsioetako edukiak eskaneatzen dira. Horrelako fitxategiak testu-datu guztiz editagarri bihurtzeko, Karaktere Optikoen Ezagutza (OCR) funtzioa duten programa bereziak erabiltzen dira.
Horrelako erabakiak oso zailak izaten dira eta, beraz, diru asko kostatzen da. PDFetik testua aldizka aitortu behar baduzu, nahiko komenigarria da programa egokia erostea. Kasu bakanetan, logikoagoa izango da antzeko funtzioak dituen lineako zerbitzu erabilgarriren bat erabiltzea.
Nola aitortu PDFa Internetetik testua
Jakina, OCR lineako zerbitzuen funtzioak, osoko mahaigaineko soluzioekin konparatuz, mugatuagoa da. Baina horrelako baliabideekin ere lan egin dezakezu dohainik edo kuota nominal batekin. Gauza nagusia zeregin nagusia da, hots, testu aitorpenarekin, dagozkien web aplikazioek ere aurre egiten diotela.
1. metodoa: ABBYY FineReader Online
Zerbitzua garatzeko enpresa dokumentu optikoen aitortzaren arloko liderretako bat da. Windows eta Mac ABBYY FineReader irtenbide indartsua da PDFa testu bihurtzeko eta horrekin lan egiteko.
Programaren web analogikoa, jakina, funtzionaltasunean baino txikiagoa da. Hala ere, zerbitzua 190 testu baino gehiagoko bilaketak eta argazkien testua antzeman daitezke. Bihur ezazu PDF fitxategiak Word, Excel eta abar dokumentuetan onartzen dira.
ABBYY FineReader lineako lineako zerbitzua
- Tresnarekin hasi aurretik, sortu kontu bat gunean edo hasi saioa Facebook, Google edo Microsoft kontua erabiliz.

Baimen leihora joateko, egin klik botoian "Login" goiko menuko barran. - Saioa hasi ondoren, inportatu nahi duzun PDF dokumentua FineReader-era botoia erabiliz "Kargatu fitxategiak".

Ondoren egin klik "Aukeratu orrialde zenbakiak" eta zehaztu nahi duzun tartea testua aitortzeko. - Ondoren, hautatu dokumentuan dauden hizkuntzak, sortutako fitxategiaren formatua eta egin klik botoian "Ezagutu".

- Prozesatu ondoren, iraupena dokumentuaren bolumenaren araberakoa denez, bukatutako fitxategia testu datuekin deskarga dezakezu bere izenean klik eginez.

Edo, esportatu hodeiko zerbitzu erabilgarriren batera.




Zerbitzua irudien eta PDF fitxategien testu errekonozimendu algoritmo zehatzenekin bereizten da. Zoritxarrez, bere erabilera doakoa hilean prozesatutako bost orrialdeetara mugatzen da. Dokumentu mamitsuagoekin lan egiteko, urteko harpidetza erosi beharko duzu.
Hala ere, OCR oso gutxitan behar bada, ABBYY FineReader Online aukera bikaina da PDF fitxategi txikietatik testua ateratzeko.
2. metodoa: Doako lineako OCR
Testua digitalizatzeko zerbitzu sinplea eta erosoa. Erregistratu gabe, baliabideak ordu osoko 15 orri PDF aitortu ditzake. Doako lineako OCR dokumentuak 46 hizkuntzatan erabat funtzionatzen du eta baimenik gabe hiru testu esportazio formatu onartzen ditu: DOCX, XLSX eta TXT.
Izena ematerakoan, erabiltzaileak orrialde anitzeko dokumentuak prozesatzeko aukera du, baina orrialde horietako kopuru librea 50 unitateetara mugatzen da.
OCR lineako lineako zerbitzua
- PDFetik testua gonbidatu gisa aitortzeko, baliabidearen baimenik gabe, erabili orrialdearen orri nagusian inprimaki egokia.

Hautatu nahi duzun dokumentua botoia erabiliz "Agiria", zehaztu testuaren hizkuntza nagusia, irteera formatua, eta itxaron fitxategia kargatu eta egin klik "Bihurtu". - Digitalizazio prozesuaren amaieran, egin klik "Deskargatu irteerako fitxategia" Amaitutako dokumentua ordenagailuan testua gordetzeko.



Baimendutako erabiltzaileentzat, ekintza sekuentzia ezberdina da.
- Erabili botoia "Izen ematea" edo "Login" goiko menuko barran, horren arabera, Doako lineako OCR kontua sortu edo bertan saioa hasteko.

- Aitorpen panelean baimena eduki ondoren, mantendu tekla «CTRL»Hautatu zerrendatik iturburu dokumentuko bi hizkuntza gehienez.

- Zehaztu aukera PDFetik testua ateratzeko aukera gehiago eta egin klik Hautatu fitxategia dokumentu bat zerbitzura igotzeko.

Ondoren, aitortza hasteko, egin klik "Bihurtu". - Dokumentua prozesatzean, egin klik dagokion zutabean irteerako fitxategiaren izenarekin dagoen estekan.

Aitorpenaren emaitza berehala gordeko da ordenagailuko memorian.




PDF dokumentu txiki batetik testua atera behar baduzu, goian aipatutako tresna erabiliz segurtasunez jo dezakezu. Fitxategi ugariekin lan egiteko, Free Online OCRan karaktere osagarriak erosi beharko dituzu edo beste irtenbide bat erabili beharko duzu.
3. metodoa: NewOCR
Guztiz doako OCR zerbitzua, DjVu eta PDF bezalako edozein dokumentu grafiko eta elektronikoetatik testua ateratzeko aukera ematen duena. Baliabideak ez du inolako murrizketarik ezartzen aitortutako fitxategien tamainari eta kopuruari, ez du erregistrorik eskatzen eta lotutako funtzio ugari eskaintzen ditu.
NewOCR-ek 106 hizkuntza onartzen ditu eta kalitate baxuko dokumentuen azterketak behar bezala prozesatu ditzake. Litekeena da fitxategiaren orrian testua aitortzeko eremua eskuz hautatzea.
NewOCR lineako zerbitzua
- Beraz, baliabide batekin lan egin dezakezu berehala, alferrikako ekintzak egin beharrik gabe.

Orrialde nagusian eskuinera dokumentu bat inportatzeko gunea dago. Fitxategia NewOCR-ra kargatzeko, erabili botoia "Aukeratu fitxategia" atalean "Hautatu fitxategia". Ondoren, eremuan "Aitortzeko hizkuntza (k)" zehaztu iturri dokumentuko hizkuntza bat edo gehiago, eta egin klik "Kargatu + OCR". - Ezarri zure gogoko ezarpen ezarpenak, hautatu testua atera nahi duzun orria eta egin klik botoian «OCR».

- Joan pixka bat orrialdetik behera eta aurkitu botoia «Jaitsi».

Egin klik gainean eta goitibeherako zerrendan hautatu deskargatzeko behar den dokumentu formatua. Horren ondoren, ateratako testuarekin amaitutako fitxategia ordenagailura deskargatuko da.



Tresna erosoa da eta nahiko kalitate handiko pertsonaiak ezagutzen ditu. Hala ere, inportatutako PDF dokumentuaren orrialde bakoitzaren prozesamendua modu independentean hasi behar da eta beste fitxategi batean bistaratzen da. Jakina, berehala kopiatu ahal izango dituzu aitorpen-emaitzak arbelean eta besteekin konbinatu.
Hala ere, goian deskribatutako ñabardura ikusita, oso zaila da NewOCR erabiliz testu kopuru handiak ateratzea. Fitxategi txikiekin, zerbitzuak kolpea ematen du.
4. metodoa: OCR.Space
Testua digitalizatzeko baliabide sinplea eta ulergarria, PDF dokumentuak aitortu eta emaitza TXT fitxategi batera ateratzeko aukera ematen du. Ez da orri kopuruari mugarik ematen. Muga bakarra da sarrerako dokumentuaren tamaina ez dela 5 megabyte baino gehiago izan behar.
OCR.Space Lineako zerbitzua
- Ez da beharrezkoa tresnarekin lan egitea.

Egin klik goiko esteka eta igo PDF dokumentua webgunera ordenagailutik botoia erabiliz "Aukeratu fitxategia" edo saretik - erreferentziaz. - Goitibeherako zerrendan "Hautatu OCR hizkuntza" Hautatu inportatutako dokumentuaren hizkuntza.

Ondoren, hasi testua ezagutzen prozesua botoian klik eginez "Hasi OCR!". - Fitxategiak prozesatzean, irakurri emaitza eremuan OCR'ed Emaitza eta egin klik «Jaitsi»amaitutako TXT dokumentua deskargatzeko.




Testua PDFetik atera behar baduzu eta aldi berean bere azken formatua ez da batere garrantzitsua, OCR.Space aukera ona da. Gauza bakarra dokumentua "elebakarra" izan behar da, aldi berean bi hizkuntza edo gehiago aitortzea zerbitzuan aurreikusten ez baita.
Ikusi ere: FineReader-en doako analogiak
Artikuluan aurkeztutako lineako tresnak ebaluatuz, esan beharra dago ABBYY-tik FineReader Online-k OCR funtzioa modu egokienean eta modu eraginkorrean kudeatzen duela. Testua aitortzeko gehienezko zehaztasuna zuretzako garrantzitsua bada, komeni da aukera hau berariaz aintzat hartzea. Baina ziurrenik, hori ere ordaindu beharko duzu.
Dokumentu txikiak digitalizatu behar badituzu eta zerbitzuan akatsak modu independentean zuzentzeko prest bazaude, komeni da NewOCR, OCR.Space edo Lineako OCR lineala erabiltzea.